Sleuth,Zipkin和Brave
先说一下Spring Cloud Sleuth, Zipkin和Brave三者之间的关系。
首先,对于Spring Cloud Sleuth来说,大家或许接触的比较多,它是Spring框架家族(在这里为什么不说是Spring Cloud框架家族,实际上这是因为Sleuth和Spring框架中的其他组成部分一样,非常灵活,即可以配合其他Spring Cloud组建,也可以不与其他的Spring Cloud组建一起使用,而仅仅作为一个Trace追踪的系统框架来试用)中的重要组成部分,为整个微服务的框架系统提供trace追踪。
关于Trace与Log的区别,推荐两篇文章:
Logging vs Tracing vs Monitoring
Logging vs. tracing
其次,是Zipkin。Zipkin是针对Trace数据进行采集、分析呈现的一套完整的框架。Zipkin的整体架构如图所示:
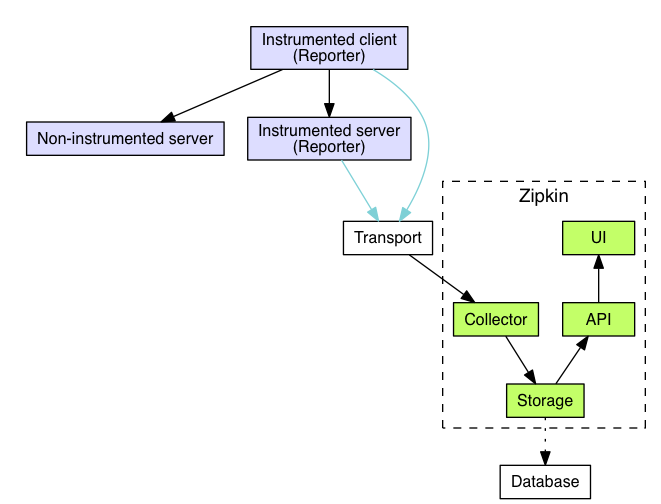
在途中可以看到,如果以ELK堆栈作为日志存储分析的框架的话,Zipkin起到的作用非常类似于Logstash和Kibana所起到的作用,即1)完成对trace数据的采集,2)实现对trace的可视化追踪。
最后,说一下Brave。Brave的官方说明为:
Brave is a library used to capture latency information about distributed operations. It reports this data to Zipkin as spans.
从这句话的字面意义来理解,brave是Zipkin的一个前端,也就是类似Zipkin架构途中的Instrumented Client的一个东西。但是,Brave的官方说明中还有另外一句:
Brave’s dependency-free tracer library works against JRE6+.
这就说明,首先的首先,Brave是一个tracer库,提供的是tracer接口。对其后台来说,可以采用Zipkin,也可以向其他的backend进行扩展。
扯了这么多,那么Sleuth,Zipkin和Brave之间到底是什么关系呢?他们的关系是这样的:
- Sleuth采用了Brave作为tracer库
- Sleuth可以不使用Zipkin
注意: 本文涉及到的Sleuth的版本为2.0+,早于2.0版本的sleuth没有使用Brave,基本上除了注解外,所有涉及到自定义时的底层接口都与本文不一致。
brave中的几个基本概念
基本概念
一般来说,trace跟踪涉及到两个概念,一个是trace,一个是span。tracer可以看作是一个逻辑执行过程中的整个链条,比如一个登陆过程的全部处理逻辑的集合就是一个tracer,而span则是trace跟踪的基本单位,比如登陆过程中访问数据库的过程可以看作是一个span。参考以下的示例代码:
1
2
3
4
5
6
7
8
9
|
// 模拟登陆函数
void login() {
dbAccess(); // 访问数据库
saveSession(); // 保存用户的seesion
}
void dbAccess() {
saveObject();
}
|
假设以上的代码是一个登陆过程。我们希望对整个登陆过程进行性能跟踪,那么对于每次执行login()的过程来说,就是我们希望追踪的一个trace,而对于dbAccess()和saveSession()两个函数来说,则是一个trace中的两个span;而对于dbAccess()来说,则saveObject()函数则是其子span。然而对于上边的基本概念,我们描述是的希望追踪的一个trace,为什么我们采用希望追踪的这样一个表述呢?这是因为,trace表述的是一次执行过程,是所有的span的集合。如果用一个图来表述的话,一个trace可以表示为:
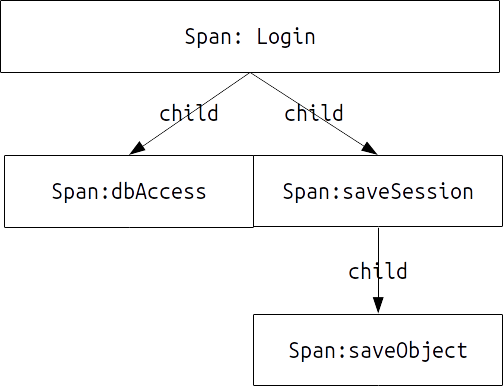
如图所示,一个trace可以看作是一个树,每个trace都有一个起点,也就是一个root span,也就是我们希望追踪的过程。而其他所有的trace都是这个root span的child span。
brave中常用的数据结构及其说明
brave提供了一组tracer工具用于实现对trace的跟踪。那么,brave中涉及到的常用的重要类主要包括:Tracing,Tracer,Span,TraceContext,Propagation五个。对这五个类的重要作用主要如下:
Tracing, 工具类,用于生成Tracer类实例。类比Log系统的话,可以看作是self4j中的LogFactory类。Tracer,也是工具类,用于生成Span。类比Log系统的话,与Logger类非常相似。!!但是!!,与Logger不同的是,在使用brave时,一般系统中存在一个全局的Tracer对象就可以了,这是因为在实际中,每个具体的trace时用一颗span构成的树来表示的。Span,实际记录每个功能块执行信息的类。TraceContext,记录trace的执行过程中的元数据信息类。创建Span的过程中,Tracer实例通过对TraceContext的操作维护Span之间的关系。TraceContext中包含的最主要的信息包括traceId,spanId, parentId和sampled,分别表示当前trace、当前span,当前span的父span,是否抽样。Propagation,用于在分布式环境或者跨进程条件下的trace跟踪时实现TraceContext传递的工具类。
Sleuth中创建trace和Span
创建一个新trace
在上一节中提到过,一个trace实际上是一个有span构成的树,因此创建一个trace实际上就是创建一个root span的过程。
创建一个新span
创建Span的过程在Sleuth中特别简单,一般来说,采用@NewSpan即可。例如,如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package net.btstream.study.cloudsleuth;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.annotation.NewSpan;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@Slf4j
public class DemoApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Override
@NewSpan
public void run(String... args) throws Exception {
log.info("Hello World");
}
}
|
在上面的这个例子中,第19行代码就开启了一个新的span,同时,由于run是入口代码,因此19行的代码实际上开始了一个root span
!!!@NewSpan的特别说明!!!
给定下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
package net.btstream.study.cloudsleuth;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.annotation.NewSpan;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@Slf4j
public class DemoApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Override
@NewSpan
public void run(String... args) throws Exception {
log.info("Hello World");
dbAccess();
}
@NewSpan
public void dbAccess(){
log.info("in dbAccess Function");
}
}
|
在上述代码中,run函数调用dbAccess函数,直觉上来说,dbAccess函数所在的span应该是run函数所在span的child span。但实际上,上述代码的实际执行结果是dbAccess函数与run函数所在的span为同一个span。
TODO: 为什么会造成结果,我没有仔细的看过@NewSpan的实现代码,但是按照Spring的尿性,应该会用到了代理,由于是同一个bean里,执行两个函数的过程是在代理内部执行的,也就绕过了dbAccess的注解。
这个问题有在sleuth官方的github的issuse中提到。参考https://github.com/spring-cloud/spring-cloud-sleuth/issues/617#issuecomment-309261811
那么,问题来了,如何使得dbAccess函数可以被放到一个单独的Span里呢?答案是采用Scoped Span。参见如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package net.btstream.study.cloudsleuth;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.annotation.NewSpan;
import brave.Span;
import brave.Tracer;
import brave.Tracer.SpanInScope;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@Slf4j
public class DemoApplication implements CommandLineRunner {
@Autowired
Tracer tracer;
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Override
@NewSpan
public void run(String... args) throws Exception {
log.info("Hello World");
Span span = tracer.nextSpan().start();
try(
SpanInScope ws = tracer.withSpanInScope(span);
){
dbAccess();
}finally {
span.finish();
}
}
@NewSpan
public void dbAccess(){
log.info("in dbAccess Function");
}
}
|
代码的29-36行定义了手动创建了一个局部的span,实现将dbAccess()的执行过程放入另一个span中。
跨进程trace追踪
最后一个问题,sleuth提供了一个在分布式系统环境下可以跨服务进行trace追踪的实现,那么这个跨服务的追踪是如何实现的呢?我们自己实现一个跨服务追踪的trace时候又该怎么做呢?
注意: sleuth和brave提供了很多不同的分布式框架的支持,例如gRPC、kafka等,可以优先考虑采用官方的提供的库。但是,对于某些特性的情况,例如基于TCP协议实现自己的通信协议的时候,如果这时希望对数据处理的全链路实现trace追踪,则需要自己实现相关的功能。
基本原理
brave实现跨服务(或者跨线程)trace追踪的核心是通过TraceContext中核心信息的传递来实现的,也就是需要把traceId,spanId, parentId, sampled四个属性在不同的服务(或进程)间实现传递,就可以实现跨服务的追踪。brave和Spring Cloud Sleuth 2.0+的官方说明上都有一张图来说明这四个属性是如何进行传递的。这个图如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Client Span Server Span
┌──────────────────┐ ┌──────────────────┐
│ │ │ │
│ TraceContext │ Http Request Headers │ TraceContext │
│ ┌──────────────┐ │ ┌───────────────────┐ │ ┌──────────────┐ │
│ │ TraceId │ │ │ X─B3─TraceId │ │ │ TraceId │ │
│ │ │ │ │ │ │ │ │ │
│ │ ParentSpanId │ │ Extract │ X─B3─ParentSpanId │ Inject │ │ ParentSpanId │ │
│ │ ├─┼─────────>│ ├────────┼>│ │ │
│ │ SpanId │ │ │ X─B3─SpanId │ │ │ SpanId │ │
│ │ │ │ │ │ │ │ │ │
│ │ Sampled │ │ │ X─B3─Sampled │ │ │ Sampled │ │
│ └──────────────┘ │ └───────────────────┘ │ └──────────────┘ │
│ │ │ │
└──────────────────┘ └──────────────────┘
|
这个图是brave针对HTTP服务进行Context传递的标准流程。即,client在传递Span的时候,会将上述四个属性填入到HTTP Request的Header中,Server端根据这些Header的信息生成一个TraceContext的实例,然后传递给Server端的Span,这样,便实现了TraceContext的传递,从而完成了跨服务追踪。
简单实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
package net.btstream.study.cloudsleuth;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import brave.Span;
import brave.Tracer;
import brave.Tracer.SpanInScope;
import brave.propagation.TraceContext;
import brave.propagation.TraceContextOrSamplingFlags;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@Slf4j
@RestController
public class DemoApplication {
@Autowired
Tracer tracer;
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Data
public static class Request {
public String traceId;
public String spanId;
public String parentSpanId;
public String sampled;
}
@GetMapping("/hello/world")
String helloWorld(Request request) {
Span span = tracer.nextSpan(parseTraceContext(request)).start();
try(SpanInScope ws = tracer.withSpanInScope(span)){
log.info("hello world");
return "hello world";
} finally {
span.finish();
}
}
private TraceContextOrSamplingFlags parseTraceContext(Request request) {
TraceContext.Builder builder = TraceContext.newBuilder();
builder.parentId(Long.parseLong(request.parentSpanId));
builder.spanId(Long.parseLong(request.spanId));
builder.traceId(Long.parseLong(request.traceId));
builder.sampled(Boolean.valueOf(request.sampled));
return TraceContextOrSamplingFlags.create(builder.build());
}
}
|
上边这段代码是一个简单的实现,实现的功能很简单,即controller从get的请求参数中获取相关的参数,调用parseTraceContext函数构造一个TraceContextOrSamplingFlags,然后通过Tracer类的nextSpan(TraceContextOrSamplingFlags)方法创建一个新的span,完成了传递。
复杂实现
上述的简单实现简单粗暴,每种实现都需要用户自己解析出来相关的数据,然后手动进行span的创建。有没有自动化的手段呢?有!就是自己实现Propagation接口,对于Propagation接口的参考实现,可以参照Brave内置的B3Propagation类。具体的展开就不再赘述了。